When
1)there is no INDEX exists
2)the table is small
3)the table has high degree of parallelism
4)query uses full table scan hint
5)stats are stale
6)query requires most of the blocks
7)When implicit conversions takes place
8)When there are NULL's
9)query predicate does not use the leading edge of an index.
FTS uses larger IO calls.This means it read multiple blocks in an instance.
Making a fewer large I/O calls is cheaper than making many smaller calls.
High-water Mark
This is a term used with table segments stored in the database. If you envision a table, for example, as a 'flat' structure or as a series of blocks laid one after the other in a line from left to right, the high-water mark (HWM) would be the rightmost block that ever contained data, as illustrated
HWM starts at the first block of a newly created table. As data is placed into the table over time and more blocks get used, the HWM rises. If we delete some (or even all) of the rows in the table, we might have many blocks that no longer contain data, but they are still under the HWM, and they will remain under the HWM until the object is rebuilt, truncated, or shrunk (shrinking of a segment is a new Oracle 10g feature that is supported only if the segment is in an ASSM tablespace).
The HWM is relevant since Oracle will scan all blocks under the HWM, even when they contain no data, during a full scan. This will impact the performance of a full scan,especially if most of the blocks under the HWM are empty. To see this, just create a table with 1,000,000 rows (or create any table with a large number of rows), and then execute a SELECT COUNT(*) from this table. Now, DELETE every row in it and you will find that the SELECT COUNT(*) takes just as long to count 0 rows as it did to count 1,000,000. This is because Oracle is busy reading all of the blocks below the HWM to see if they contain data. You should compare this to what happens if you used TRUNCATE on the table instead of deleting each individual row. TRUNCATE will reset the HWM of a table back to 'zero' and will truncate the associated indexes on the table as well. If you plan on deleting every row in a table, TRUNCATE;if it can be used it would be the method of choice for this reason.
In an MSSM tablespace, segments have a definite HWM. In an ASSM tablespace, however, there is an HWM and a low HWM. In MSSM, when the HWM is advanced (e.g., as rows are inserted), all of the blocks are formatted and valid, and Oracle can read them safely. With ASSM, however, when the HWM is advanced Oracle doesn't format all of the blocks immediately they are only formatted and made safe to read upon their first use. So, when full scanning a segment, we have to know if the blocks to be read are 'safe' or unformatted (meaning they contain nothing of interest and we do not process them). To make it so that not every block in the table need go through this safe/not safe check, Oracle maintains a low HWM and a HWM. Oracle will full scan the table up to the HWM and for all of the blocks below the low HWM, it will just read and process them. For blocks between the 'low HWM' and the HWM, it must be more careful and refer to the ASSM bitmap information used to manage these blocks in order to see which of them it should read and which it should just ignore.
MSSM-Manual Segment Space Management --Free space is maintained by Freelist
ASSM-Automatic Segment Space Management--Free Space is maintained by Bitmaps.
1)there is no INDEX exists
2)the table is small
3)the table has high degree of parallelism
4)query uses full table scan hint
5)stats are stale
6)query requires most of the blocks
7)When implicit conversions takes place
8)When there are NULL's
9)query predicate does not use the leading edge of an index.
FTS uses larger IO calls.This means it read multiple blocks in an instance.
Making a fewer large I/O calls is cheaper than making many smaller calls.
High-water Mark
This is a term used with table segments stored in the database. If you envision a table, for example, as a 'flat' structure or as a series of blocks laid one after the other in a line from left to right, the high-water mark (HWM) would be the rightmost block that ever contained data, as illustrated
+---- high water mark of newly created table
|
V
+--------------------------------------------------------+
| | | | | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | | | | |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
high water mark after inserting 10,000 rows
|
v
+--------------------------------------------------------+
|x |x |x |x |x |x |x |x |x |x |x |x | | | | | | | |
|x |x |x |x |x |x |x |x |x |x |x |x | | | | | | | |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
high water mark after inserting 10,000 rows
|
v
+--------------------------------------------------------+
|x |x |x |x |x |x |x | | | | | | | | | | | | |
|x |x |x |x |x |x |x | | | | | | | | | | | | |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
HWM starts at the first block of a newly created table. As data is placed into the table over time and more blocks get used, the HWM rises. If we delete some (or even all) of the rows in the table, we might have many blocks that no longer contain data, but they are still under the HWM, and they will remain under the HWM until the object is rebuilt, truncated, or shrunk (shrinking of a segment is a new Oracle 10g feature that is supported only if the segment is in an ASSM tablespace).
The HWM is relevant since Oracle will scan all blocks under the HWM, even when they contain no data, during a full scan. This will impact the performance of a full scan,especially if most of the blocks under the HWM are empty. To see this, just create a table with 1,000,000 rows (or create any table with a large number of rows), and then execute a SELECT COUNT(*) from this table. Now, DELETE every row in it and you will find that the SELECT COUNT(*) takes just as long to count 0 rows as it did to count 1,000,000. This is because Oracle is busy reading all of the blocks below the HWM to see if they contain data. You should compare this to what happens if you used TRUNCATE on the table instead of deleting each individual row. TRUNCATE will reset the HWM of a table back to 'zero' and will truncate the associated indexes on the table as well. If you plan on deleting every row in a table, TRUNCATE;if it can be used it would be the method of choice for this reason.
In an MSSM tablespace, segments have a definite HWM. In an ASSM tablespace, however, there is an HWM and a low HWM. In MSSM, when the HWM is advanced (e.g., as rows are inserted), all of the blocks are formatted and valid, and Oracle can read them safely. With ASSM, however, when the HWM is advanced Oracle doesn't format all of the blocks immediately they are only formatted and made safe to read upon their first use. So, when full scanning a segment, we have to know if the blocks to be read are 'safe' or unformatted (meaning they contain nothing of interest and we do not process them). To make it so that not every block in the table need go through this safe/not safe check, Oracle maintains a low HWM and a HWM. Oracle will full scan the table up to the HWM and for all of the blocks below the low HWM, it will just read and process them. For blocks between the 'low HWM' and the HWM, it must be more careful and refer to the ASSM bitmap information used to manage these blocks in order to see which of them it should read and which it should just ignore.
MSSM-Manual Segment Space Management --Free space is maintained by Freelist
ASSM-Automatic Segment Space Management--Free Space is maintained by Bitmaps.







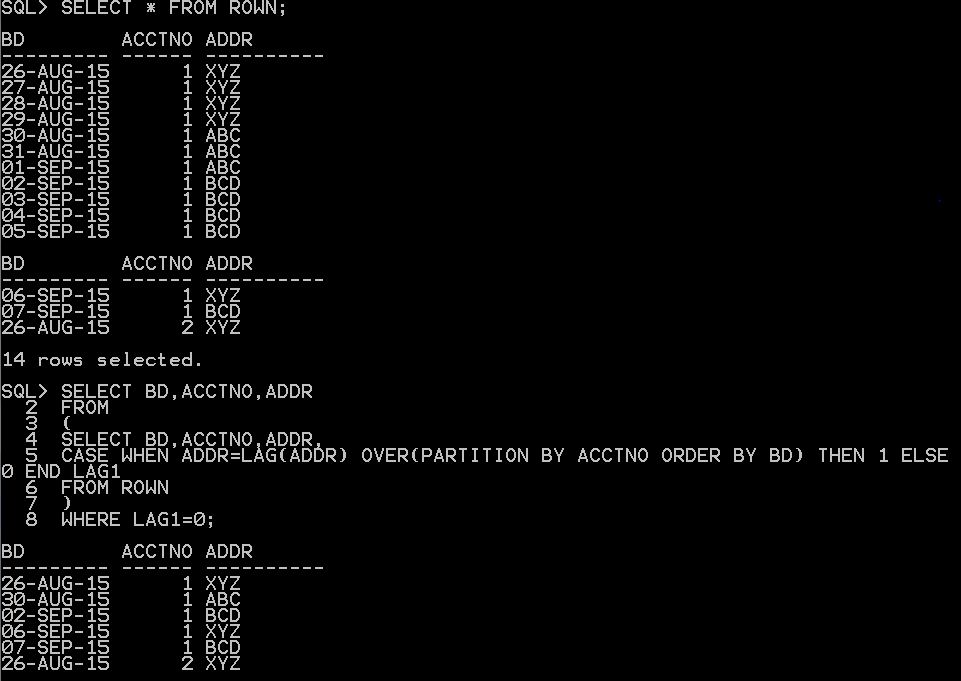




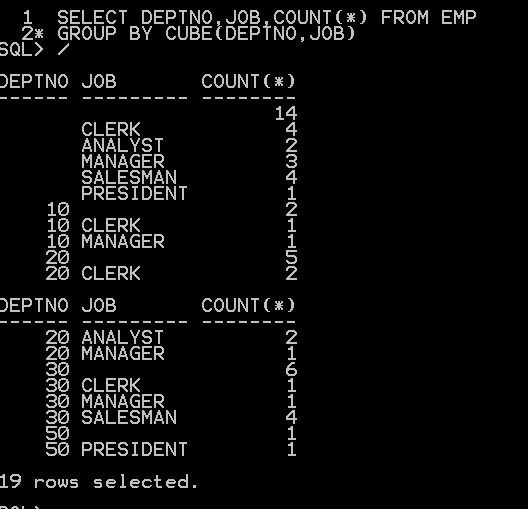
























INS INTO KBB VALUES('2014-01-01','A');
INS INTO KBB VALUES('2014-01-02','A');
INS INTO KBB VALUES('2014-01-03','D');
INS INTO KBB VALUES('2014-01-04','A');
INS INTO KBB VALUES('2014-01-05','D');
INS INTO KBB VALUES('2014-01-06','A');
FROM KBB