I have a column and value is 1,2,3,4,5,6. Need to split this value into rows.
Note: 1,2,3,4,5,6 is a single value under column.





 |

+---- high water mark of newly created table
|
V
+--------------------------------------------------------+
| | | | | | | | | | | | | | | | | | | |
| | | | | | | | | | | | | | | | | | | |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
high water mark after inserting 10,000 rows
|
v
+--------------------------------------------------------+
|x |x |x |x |x |x |x |x |x |x |x |x | | | | | | | |
|x |x |x |x |x |x |x |x |x |x |x |x | | | | | | | |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
high water mark after inserting 10,000 rows
|
v
+--------------------------------------------------------+
|x |x |x |x |x |x |x | | | | | | | | | | | | |
|x |x |x |x |x |x |x | | | | | | | | | | | | |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+




SQL> select * from t1;
DEPT DATE1
---------- ---------
100 01-JAN-13
100 02-JAN-13
200 03-JAN-13
100 04-JAN-13
select dept,
date1,
rank () Over (partition by dept order by date1) rnk
from t1
order by date1;
DEPT DATE1 RNK
---------- --------- ----------
100 01-JAN-13 1
100 02-JAN-13 2
200 03-JAN-13 1
100 04-JAN-13 3 DEPT DATE1 RNK
---------- --------- ----------
100 01-JAN-13 1
100 02-JAN-13 2
200 03-JAN-13 1
100 04-JAN-13 1 <<<----------Solution:select dept, date1,
CASE WHEN StartFlag = 0 THEN 1
ELSE 1+StartFlag+NVL(lag(StartFlag) over (order by date1),0)
END as rnk
from (select t1.*,
(case when dept = lag(dept) over (order by date1)
then 1
else 0
end) as StartFlag
from t1
) t1
order by date1;
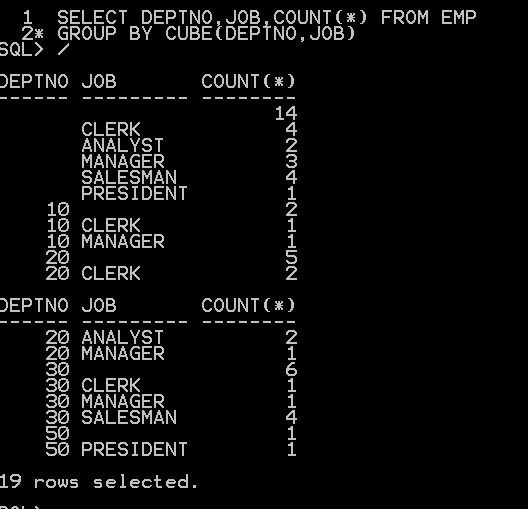
GROUPING_ID function provides an alternate and more compact way to identify subtotal rows. Passing the dimension columns as arguments, it returns a number indicating the GROUP BY level.












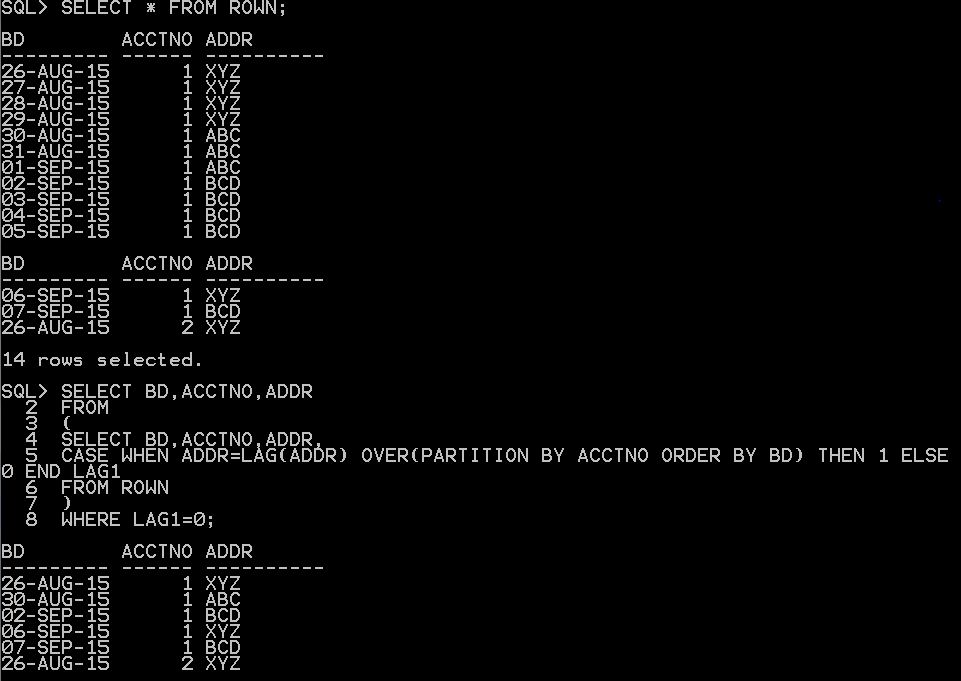




















INS INTO KBB VALUES('2014-01-01','A');
INS INTO KBB VALUES('2014-01-02','A');
INS INTO KBB VALUES('2014-01-03','D');
INS INTO KBB VALUES('2014-01-04','A');
INS INTO KBB VALUES('2014-01-05','D');
INS INTO KBB VALUES('2014-01-06','A');
FROM KBB