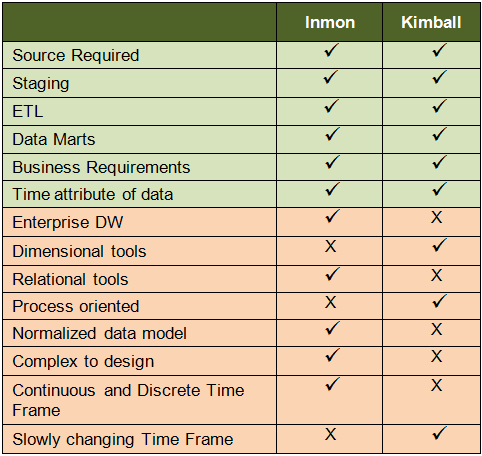
The dimensional approach, made popular by in Ralph Kimball (website), states that the data warehouse should be modeled using a Dimensional Model (star schema or snowflake). The normalized approach, also called the 3NF model, made popular by Bill Inmon (website), states that the data warehouse should be modeled using an E-R model/normalized model.
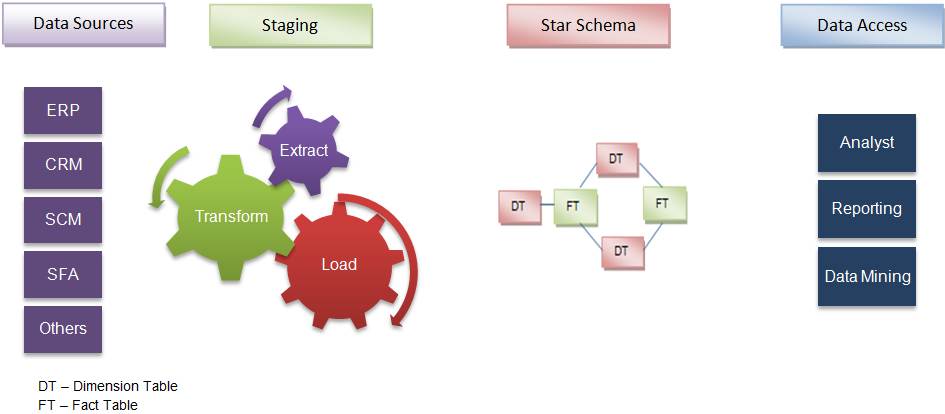
In a dimensional approach, data is partitioned into either “facts”, which are generally numeric transaction data, or “dimensions“, which are the reference information that gives context to the facts. A key advantage of a dimensional approach is that the data warehouse is easier for the user to understand and to use. Also, the retrieval of data from the data warehouse tends to operate very quickly. The main disadvantage of the dimensional approach is that In order to maintain the integrity of facts and dimensions, loading the data warehouse with data from different operational systems is complicated. Plus, if you are used to working with a normalized approach, it can take a while to fully understand the dimensional approach and to become efficient in building one.
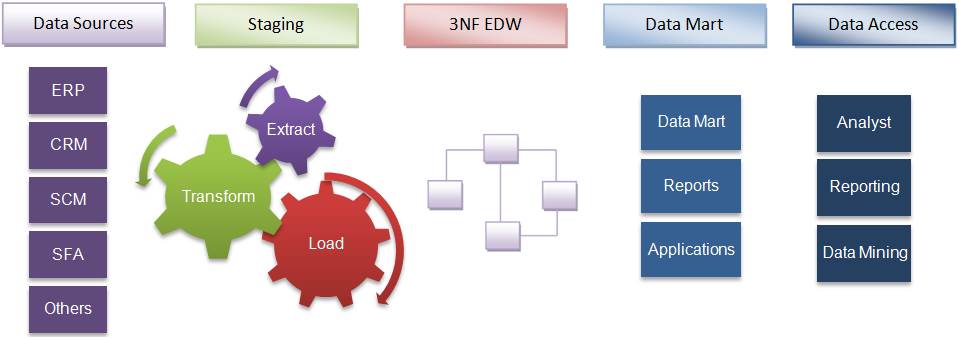
In the normalized approach, the data in the data warehouse are stored following database normalization rules. Tables are grouped together by subject areas that reflect general data categories (e.g., data on customers, products, finance, etc.). The normalized structure divides data into entities, which creates several tables in a relational database. When applied in large enterprises the result is dozens of tables that are linked together by a web of joins. Furthermore, each of the created entities is converted into separate physical tables when the database is implemented. The main advantage of this approach is that it is straightforward to add information into the database. A disadvantage of this approach is that, because of the number of tables involved, it can be difficult for users both to join data from different sources into meaningful information and then access the information without a precise understanding of the sources of data and of the data structure of the data warehouse.
In a dimensional approach, data is partitioned into either “facts”, which are generally numeric transaction data, or “dimensions“, which are the reference information that gives context to the facts. A key advantage of a dimensional approach is that the data warehouse is easier for the user to understand and to use. Also, the retrieval of data from the data warehouse tends to operate very quickly. The main disadvantage of the dimensional approach is that In order to maintain the integrity of facts and dimensions, loading the data warehouse with data from different operational systems is complicated. Plus, if you are used to working with a normalized approach, it can take a while to fully understand the dimensional approach and to become efficient in building one.
In the normalized approach, the data in the data warehouse are stored following database normalization rules. Tables are grouped together by subject areas that reflect general data categories (e.g., data on customers, products, finance, etc.). The normalized structure divides data into entities, which creates several tables in a relational database. When applied in large enterprises the result is dozens of tables that are linked together by a web of joins. Furthermore, each of the created entities is converted into separate physical tables when the database is implemented. The main advantage of this approach is that it is straightforward to add information into the database. A disadvantage of this approach is that, because of the number of tables involved, it can be difficult for users both to join data from different sources into meaningful information and then access the information without a precise understanding of the sources of data and of the data structure of the data warehouse.























{kind=link}