
Thursday, 27 August 2015
Wednesday, 26 August 2015

Saturday, 15 August 2015
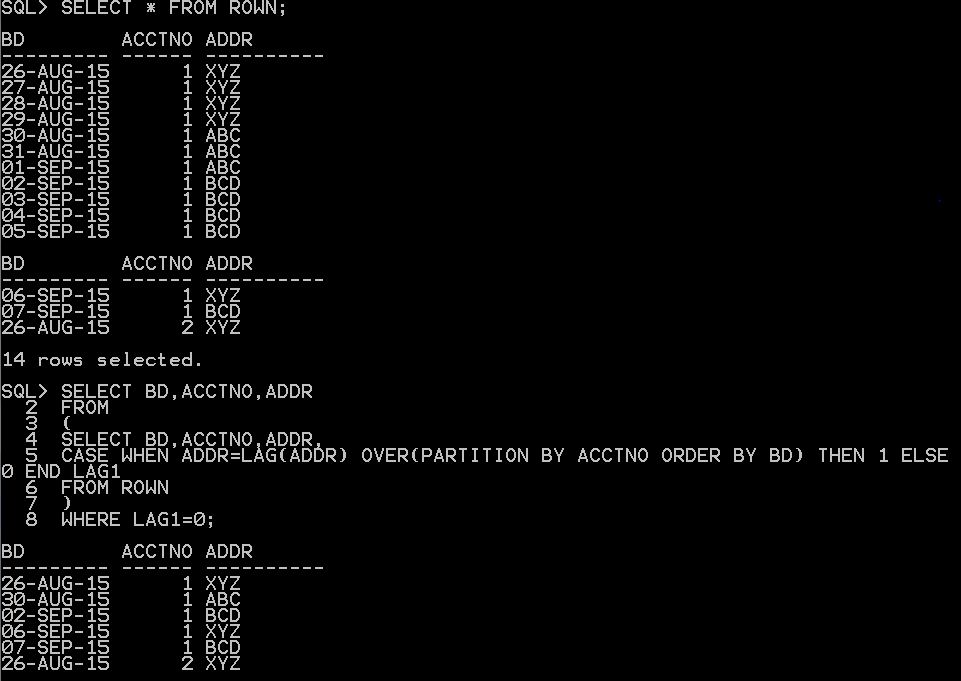
RESET a RANK
SQL> select * from t1;
DEPT DATE1
---------- ---------
100 01-JAN-13
100 02-JAN-13
200 03-JAN-13
100 04-JAN-13
select dept,
date1,
rank () Over (partition by dept order by date1) rnk
from t1
order by date1;
DEPT DATE1 RNK
---------- --------- ----------
100 01-JAN-13 1
100 02-JAN-13 2
200 03-JAN-13 1
100 04-JAN-13 3
The desired output is as follows. The last rnk=1 is becuase the Jan-04 record is the first record after the change.
DEPT DATE1 RNK
---------- --------- ----------
100 01-JAN-13 1
100 02-JAN-13 2
200 03-JAN-13 1
100 04-JAN-13 1 <<<----------Solution:select dept, date1,
CASE WHEN StartFlag = 0 THEN 1
ELSE 1+StartFlag+NVL(lag(StartFlag) over (order by date1),0)
END as rnk
from (select t1.*,
(case when dept = lag(dept) over (order by date1)
then 1
else 0
end) as StartFlag
from t1
) t1
order by date1;
Friday, 14 August 2015
CUBE, ROLLUP , GROUPING SETS & GROUPING_ID
The
GROUPING_ID function provides an alternate and more compact way to identify subtotal rows. Passing the dimension columns as arguments, it returns a number indicating the GROUP BY level.



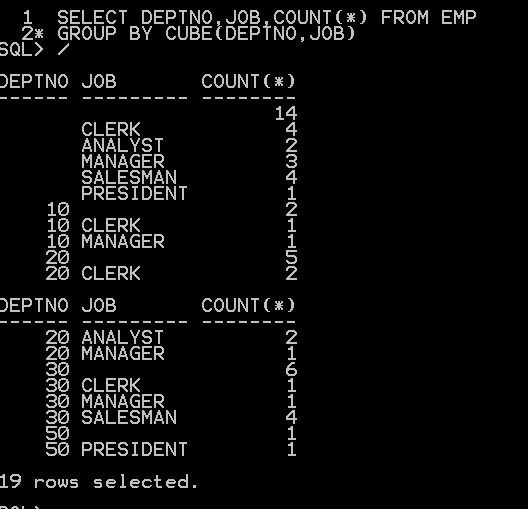
CUBE, ROLLUP and GROUPING SETS
The CUBE, ROLLUP and GROUPING SETS functions are used in the GROUP BY clause to generate totals and subtotals.
ROLLUP can have more than one dimension, generating grand totals and subtotals:

ROLLUP can have more than one dimension, generating grand totals and subtotals:



Tuesday, 11 August 2015

Saturday, 8 August 2015
Complex SQL Scenario
Get the deptno from employee table that are not in dept table and deptno from dept table that are not in employee table without using SET operators.
SELECT
COALESCE(DEPT.DEPTNO,EMP.DEPTNO)
FROM
EMP
FULL OUTER JOIN
DEPT
ON EMP.DEPTNO=DEPT.DEPTNO
WHERE EMPNO IS NULL OR DNAME IS NULL
/
SELECT
COALESCE(DEPT.DEPTNO,EMP.DEPTNO)
FROM
EMP
FULL OUTER JOIN
DEPT
ON EMP.DEPTNO=DEPT.DEPTNO
WHERE EMPNO IS NULL OR DNAME IS NULL
/
Friday, 7 August 2015
Thursday, 6 August 2015
Residual Condition in Explain Plan
Residual condition means a filter is applied on particular table to limit the number of rows fetched into Spool.
Say for example
Sel * from EMP where sal > 1000;
Say for example
Sel * from EMP where sal > 1000;
Pseudo Table in Explain Plan
It is a false lock which is applied on the table to prevent two users from getting conflicting locks with all-AMP requests.
PE will determine an particular AMP to manage all AMP LOCK requests for given table and Put Pseudo lock on the table.
To put in Simple terms , its like an University with 10 gates and at a given time you can enter the university through one gate ( or main gate) for security check.
PE will determine an particular AMP to manage all AMP LOCK requests for given table and Put Pseudo lock on the table.
To put in Simple terms , its like an University with 10 gates and at a given time you can enter the university through one gate ( or main gate) for security check.
Reasons for product joins
1. Stale or no stats causing optimizer to use product join
2. Improper usage of aliases in the query.
3. missing where clause ( or Cartesian product join 1=1 )
4. non equality conditions like > ,< , between example ( date)
5. few join conditions
6. when or conditions are used.
last but not the least product joins are not bad always!! sometimes PJ are better compared to other types of joins
Different types of skews
If you utilized unequally TD resources (CPU,AMP,IO,Disk and etc) this is called skew exists. Major are 3 types of skews (CPU skew, AMP/Data skew, IO Skew).
-Data skew?
When data is not distributed equally on all the AMPs.
-Cpu skew?
Who is taking/consuming more CPU called cpu skew.
-IO skew?
Who perform more IO Operation? Resulting in IO Skew
-Data skew?
When data is not distributed equally on all the AMPs.
-Cpu skew?
Who is taking/consuming more CPU called cpu skew.
-IO skew?
Who perform more IO Operation? Resulting in IO Skew
TENACITY and it's default value
- TENACITY specifies the amount of time in hours, to retry to obtain a loader slot or to establish all requested sessions to logon.
- The default for Fast Load is “no tenacity”, meaning that it will not retry at all.
- If several FastLoad jobs are executed at the same time, we recommend setting the TENACITY to 4, meaning that the system will continue trying to logon for the number of sessions requested for up to four hours.
Query to find the skew factor in Teradata
SELECT
TABLENAME,
SUM(CURRENTPERM) /(1024*1024) AS CURRENTPERM,
(100 - (AVG(CURRENTPERM)/MAX(CURRENTPERM)*100)) AS SKEWFACTOR
FROM
DBC.TABLESIZE
WHERE DATABASENAME= <DATABASENAME>
AND
TABLENAME =<TABLENAME>
GROUP BY 1;
TABLENAME,
SUM(CURRENTPERM) /(1024*1024) AS CURRENTPERM,
(100 - (AVG(CURRENTPERM)/MAX(CURRENTPERM)*100)) AS SKEWFACTOR
FROM
DBC.TABLESIZE
WHERE DATABASENAME= <DATABASENAME>
AND
TABLENAME =<TABLENAME>
GROUP BY 1;
Acceptable range for skew factor in a table
There is no particular range for skew factor. In case of production systems, it is suggested to keep skew factor between 5-10.
There are various considerations for skew factor
- Number of AMPS
- Size of row in a table
- number of records in a table
- PI of a table
- Frequent access of table (Performance consideration)
- whether table getting loaded daily /monthly or how frequently data is being refreshed
Tuesday, 4 August 2015
How to skip the header row in the fastload script
RECORD 2; /* this skips first record in the source file */
Why Fload doesn’t support multiset table in Teradata?
Fload does not support Multiset table because of restart capability.
Say, the fastload job fails. Till the fastload failed, some number of rows was sent to the AMP's.
Now if you restart FLOAD, it would start loading record from the last checkpoint and some of the consecutive rows are sent for the second time. These will be caught as duplicate rows are found after sorting of data.
This restart logic is the reason that Fastload will not load duplicate rows into a MULTISET table. It assumes they are duplicates because of this logic. Fastload support Multiset table but does not support the duplicate rows. Multiset tables are tables that allow duplicate rows. When Fastload finds the duplicate rows it discards it. Fast Load can load data into multiset table but will not load the duplicate rows
What are the types of HASH functions used in Teradata?
These are the types of HASH, HASHROW, HASHAMP and HASHBAKAMP. Their SQL functions are-
HASHROW (column(s))
HASHBUCKET (hashrow)
HASHAMP (hashbucket)
HASHBAKAMP (hashbucket)
To find the data distribution of a table based on PI, below query will be helpful. This query will give the number of records in each AMP for that particular table.
SELECT HASHAMP(HASHBUCKET(HASHROW(PI_COLUMN))),COUNT(*) FROM TABLENBAME GROUP BY 1.
How to create a table with an existing structure of another table with or without data and also with stats defined in Teradata?
CREATE TABLE new_TABLE AS old_TABLE WITH DATA;
CREATE TABLE new_TABLE AS old_TABLE WITH NO DATA;
CREATE TABLE new_TABLE AS old_TABLE WITH DATA AND STATS;
How to calculate the tablesize , database size and free space left in a database in teradata?
DBC.TABLESIZE and DBC.DISKSPACE are the systems tables used to find the space occupied.
Below Query gives the table size of each tables in the database and it will be useful to find the big tables in case of any space recovery.
SELECT DATABASENAME,
TABLENAME,
SUM(CURRENTPERM/(1024*1024*1024)) AS "TABLE SIZE"
FROM
DBC.TABLESIZE
WHERE
DATABASENAME = 'DATABASE_NAME' AND TABLENAME = 'TABLE_NAME'
GROUP BY 1,2;
Below query gives the total space and free space available in a database.
SELECT
DATABASENAME DATABASE_NAME,
SUM(MAXPERM)/(1024*1024*1024) TOTAL_PERM_SPACE,
SUM(CURRENTPERM)/(1024*1024*1024) CURRENT_PERM_SPACE,
TOTAL_PERM_SPACE-CURRENT_PERM_SPACE as FREE_SPACE
FROM
DBC.DISKSPACE
WHERE
DATABASENAME = 'DATABASE_NAME'
group by 1;














Sunday, 2 August 2015
Unix command to calculate the maximum length of a column in a file
I have a scenario where I have to find the maximum length of the data in a column in file.
Here, the column i need to find is for 12th column.
awk -F'|' 'NR>1{for (i=12; i<=12; i++) max[i]=(length($i)>max[i]?length($i):max[i])} END {for (i=12; i<=12; i++) printf "%d%s", max[i], (i==12?RS:FS)}' BETA.PAD.AUDIT.DAT
Here, the column i need to find is for 12th column.
awk -F'|' 'NR>1{for (i=12; i<=12; i++) max[i]=(length($i)>max[i]?length($i):max[i])} END {for (i=12; i<=12; i++) printf "%d%s", max[i], (i==12?RS:FS)}' BETA.PAD.AUDIT.DAT
Find the maximum length of a line in a Unix file
awk ' { if ( length > L ) { L=length} }END{ print L}' <Filename>
Saturday, 1 August 2015
Two MultiLoad Modes: IMPORT and DELETE
MultiLoad provides two types of operations via modes: IMPORT and DELETE. In MultiLoad
IMPORT mode, you have the freedom to "mix and match" up to twenty (20) INSERTs, UPDATEs or
DELETEs on up to five target tables. The execution of the DML statements is not mandatory for all
rows in a table. Instead, their execution hinges upon the conditions contained in the APPLY clause
of the script. Once again, MultiLoad demonstrates its user-friendly flexibility. For UPDATEs or
DELETEs to be successful in IMPORT mode, they must reference the Primary Index in the WHERE
clause.
The MultiLoad DELETE mode is used to perform a global (all AMP) delete on just one table. The
reason to use .BEGIN DELETE MLOAD is that it bypasses the Transient Journal (TJ) and can be
RESTARTed if an error causes it to terminate prior to finishing. When performing in DELETE mode,
the DELETE SQL statement cannot reference the Primary Index in the WHERE clause. This due to
the fact that a primary index access is to a specific AMP; this is a global operation.
The other factor that makes a DELETE mode operation so good is that it examines an entire block
of rows at a time. Once all the eligible rows have been removed, the block is written one time and a
checkpoint is written. So, if a restart is necessary, it simply starts deleting rows from the next block
without a checkpoint. This is a smart way to continue. Remember, when using the TJ all deleted
rows are put back into the table from the TJ as a rollback. A rollback can take longer to finish then
the delete. MultiLoad does not do a rollback; it does a restart.
IMPORT mode, you have the freedom to "mix and match" up to twenty (20) INSERTs, UPDATEs or
DELETEs on up to five target tables. The execution of the DML statements is not mandatory for all
rows in a table. Instead, their execution hinges upon the conditions contained in the APPLY clause
of the script. Once again, MultiLoad demonstrates its user-friendly flexibility. For UPDATEs or
DELETEs to be successful in IMPORT mode, they must reference the Primary Index in the WHERE
clause.
The MultiLoad DELETE mode is used to perform a global (all AMP) delete on just one table. The
reason to use .BEGIN DELETE MLOAD is that it bypasses the Transient Journal (TJ) and can be
RESTARTed if an error causes it to terminate prior to finishing. When performing in DELETE mode,
the DELETE SQL statement cannot reference the Primary Index in the WHERE clause. This due to
the fact that a primary index access is to a specific AMP; this is a global operation.
The other factor that makes a DELETE mode operation so good is that it examines an entire block
of rows at a time. Once all the eligible rows have been removed, the block is written one time and a
checkpoint is written. So, if a restart is necessary, it simply starts deleting rows from the next block
without a checkpoint. This is a smart way to continue. Remember, when using the TJ all deleted
rows are put back into the table from the TJ as a rollback. A rollback can take longer to finish then
the delete. MultiLoad does not do a rollback; it does a restart.
Find the bad record in a file using Sed and AWK command
I have a file which has 23 million records loading into a stage table using Informatica.
Suddenly there is a failure due to bad record in between loading.Our file delimiter is " | " pipe.
There is an extra pipe in between the fields. My file has 11 fields.
sed -n '14409589,2300000p' <filename>| awk -F "|" 'NF != 11'
returns the rows that have more than 11 columns.
Subscribe to:
Comments (Atom)
INS INTO KBB VALUES('2014-01-01','A');
INS INTO KBB VALUES('2014-01-02','A');
INS INTO KBB VALUES('2014-01-03','D');
INS INTO KBB VALUES('2014-01-04','A');
INS INTO KBB VALUES('2014-01-05','D');
INS INTO KBB VALUES('2014-01-06','A');
FROM KBB